Python Integration with ClickHouse Connect
Introduction
ClickHouse Connect is a core database driver providing interoperability with a wide range of Python applications.
- The main interface is the
Clientobject in the packageclickhouse_connect.driver. That core package also includes assorted helper classes and utility functions used for communicating with the ClickHouse server and "context" implementations for advanced management of insert and select queries. - The
clickhouse_connect.datatypespackage provides a base implementation and subclasses for all non-experimental ClickHouse datatypes. Its primary functionality is serialization and deserialization of ClickHouse data into the ClickHouse "Native" binary columnar format, used to achieve the most efficient transport between ClickHouse and client applications. - The Cython/C classes in the
clickhouse_connect.cdriverpackage optimize some of the most common serializations and deserializations for significantly improved performance over pure Python. - There is a limited SQLAlchemy dialect in the package
clickhouse_connect.cc_sqlalchemywhich is built off of thedatatypesanddbipackes. This restricted implementation focuses on query/cursor functionality, and does not generally support SQLAlchemy DDL and ORM operations. (SQLAlchemy is targeted toward OLTP databases, and we recommend more specialized tools and frameworks to manage the ClickHouse OLAP oriented database.) - The core drive and ClickHouse Connect SQLAlchemy implementation are the preferred method for connecting ClickHouse
to Apache Superset. Use the
ClickHouse Connectdatabase connection, orclickhousedbSQLAlchemy dialect connection string.
This documentation is current as of the beta release 0.7.7.
The official ClickHouse Connect Python driver uses HTTP protocol for communication with the ClickHouse server. It has some advantages (like better flexibility, HTTP-balancers support, better compatibility with JDBC-based tools, etc) and disadvantages (like slightly lower compression and performance, and a lack of support for some complex features of the native TCP-based protocol). For some use cases, you may consider using one of the Community Python drivers that uses native TCP-based protocol.
Requirements and Compatibility
| Python | Platform¹ | ClickHouse | SQLAlchemy² | Apache Superset | |||||
|---|---|---|---|---|---|---|---|---|---|
| 2.x, <3.8 | ❌ | Linux (x86) | ✅ | <23.8³ | 🟡 | <1.3 | ❌ | <1.4 | ❌ |
| 3.8.x | ✅ | Linux (Aarch64) | ✅ | 23.8.x | ✅ | 1.3.x | ✅ | 1.4.x | ✅ |
| 3.9.x | ✅ | macOS (x86) | ✅ | 23.9-23.12³ | 🟡 | 1.4.x | ✅ | 1.5.x | ✅ |
| 3.10.x | ✅ | macOS (ARM) | ✅ | 24.1.x | ✅ | >=2.x | ❌ | 2.0.x | ✅ |
| 3.11.x | ✅ | Windows | ✅ | 24.2.x | ✅ | 2.1.x | ✅ | ||
| 3.12.x | ✅ | 24.3.x | ✅ | 3.0.x | ✅ |
¹ClickHouse Connect has been explicitly tested against the listed platforms. In addition, untested binary wheels (with C optimization) are built for all architectures supported by the excellent cibuildwheel project. Finally, because ClickHouse Connect can also run as pure Python, the source installation should work on any recent Python installation.
²Again SQLAlchemy support is limited primarily to query functionality. The full SQLAlchemy API is not supported.
³ClickHouse Connect has been tested against all currently supported ClickHouse versions. Because it uses the HTTP protocol, it should also work correctly for most other versions of ClickHouse, although there may be some incompatibilities with certain advanced data types.
Installation
Install ClickHouse Connect from PyPI via pip:
pip install clickhouse-connect
ClickHouse Connect can also be installed from source:
git clonethe GitHub repository.- (Optional) run
pip install cythonto build and enable the C/Cython optimizations cdto the project root directory and runpip install .
Support Policy
ClickHouse Connect is currently in beta and only the current beta release is actively supported. Please update to the
latest version before reported any issues. Issues should be filed in the GitHub project. Future releases of
ClickHouse Connect are guaranteed to be compatible with actively supported ClickHouse versions at the time of release
(generally the three most recent stable and two most recent lts releases).
Basic Usage
Gather your connection details
To connect to ClickHouse with HTTP(S) you need this information:
The HOST and PORT: typically, the port is 8443 when using TLS or 8123 when not using TLS.
The DATABASE NAME: out of the box, there is a database named
default, use the name of the database that you want to connect to.The USERNAME and PASSWORD: out of the box, the username is
default. Use the username appropriate for your use case.
The details for your ClickHouse Cloud service are available in the ClickHouse Cloud console. Select the service that you will connect to and click Connect:
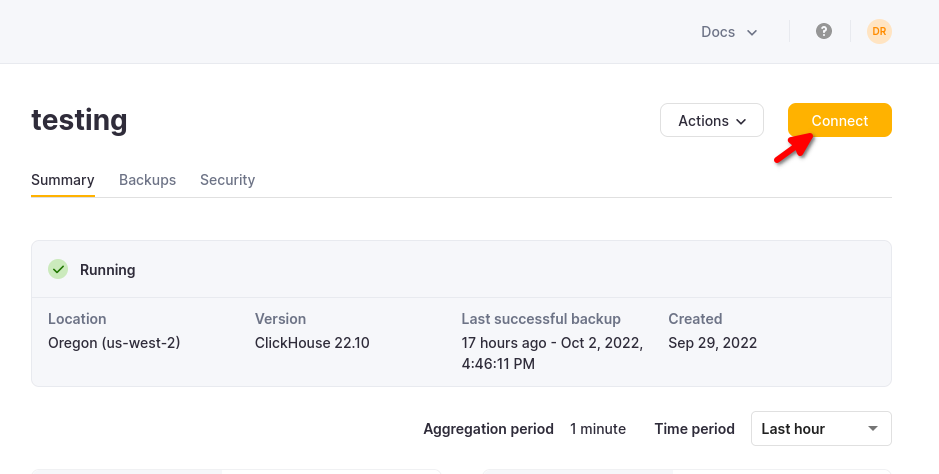
Choose HTTPS, and the details are available in an example curl command.
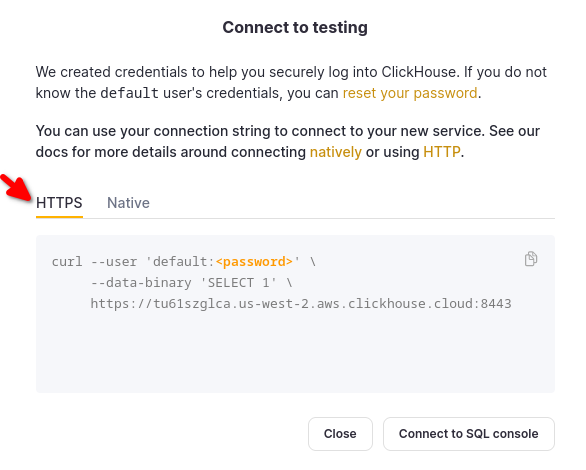
If you are using self-managed ClickHouse, the connection details are set by your ClickHouse administrator.
Establish a connection
There are two examples shown for connecting to ClickHouse:
- Connecting to a ClickHouse server on localhost.
- Connecting to a ClickHouse Cloud service.
Use a ClickHouse Connect client instance to connect to a ClickHouse server on localhost:
import clickhouse_connect
client = clickhouse_connect.get_client(host='localhost', username='default', password='password')
Use a ClickHouse Connect client instance to connect to a ClickHouse Cloud service:
Use the connection details gathered earlier. ClickHouse Cloud services require TLS, so use port 8443.
import clickhouse_connect
client = clickhouse_connect.get_client(host='HOSTNAME.clickhouse.cloud', port=8443, username='default', password='your password')
Interact with your database
To run a ClickHouse SQL command, use the client command method:
client.command('CREATE TABLE new_table (key UInt32, value String, metric Float64) ENGINE MergeTree ORDER BY key')
To insert batch data, use the client insert method with a two-dimensional array of rows and values:
row1 = [1000, 'String Value 1000', 5.233]
row2 = [2000, 'String Value 2000', -107.04]
data = [row1, row2]
client.insert('new_table', data, column_names=['key', 'value', 'metric'])
To retrieve data using ClickHouse SQL, use the client query method:
result = client.query('SELECT max(key), avg(metric) FROM new_table')
result.result_rows
Out[13]: [(2000, -50.9035)]
ClickHouse Connect Driver API
Note: Passing keyword arguments is recommended for most api methods given the number of possible arguments, most of which are optional.
Client Initialization
The clickhouse_connect.driver.client class provides the primary interface between a Python application and the
ClickHouse database server. Use the clickhouse_connect.get_client function to obtain a Client instance, which accepts
the following arguments:
Connection Arguments
| Parameter | Type | Default | Description |
|---|---|---|---|
| interface | str | http | Must be http or https. |
| host | str | localhost | The hostname or IP address of the ClickHouse server. If not set, localhost will be used. |
| port | int | 8123 or 8443 | The ClickHouse HTTP or HTTPS port. If not set will default to 8123, or to 8443 if secure=True or interface=https. |
| username | str | default | The ClickHouse user name. If not set, the default ClickHouse user will be used. |
| password | str | <empty string> | The password for username. |
| database | str | None | The default database for the connection. If not set, ClickHouse Connect will use the default database for username. |
| secure | bool | False | Use https/TLS. This overrides inferred values from the interface or port arguments. |
| dsn | str | None | A string in standard DSN (Data Source Name) format. Other connection values (such as host or user) will be extracted from this string if not set otherwise. |
| compress | bool or str | True | Enable compression for ClickHouse HTTP inserts and query results. See Additional Options (Compression) |
| query_limit | int | 0 (unlimited) | Maximum number of rows to return for any query response. Set this to zero to return unlimited rows. Note that large query limits may result in out of memory exceptions if results are not streamed, as all results are loaded into memory at once. |
| query_retries | int | 2 | Maximum number of retries for a query request. Only "retryable" HTTP responses will be retried. command or insert requests are not automatically retried by the driver to prevent unintended duplicate requests. |
| connect_timeout | int | 10 | HTTP connection timeout in seconds. |
| send_receive_timeout | int | 300 | Send/receive timeout for the HTTP connection in seconds. |
| client_name | str | None | client_name prepended to the HTTP User Agent header. Set this to track client queries in the ClickHouse system.query_log. |
| pool_mgr | obj | <default PoolManager> | The urllib3 library PoolManager to use. For advanced use cases requiring multiple connection pools to different hosts. |
| http_proxy | str | None | HTTP proxy address (equivalent to setting the HTTP_PROXY environment variable). |
| https_proxy | str | None | HTTPS proxy address (equivalent to setting the HTTPS_PROXY environment variable). |
| apply_server_timezone | bool | True | Use server timezone for timezone aware query results. See [Timezone Precedence])(#time-zones) |
HTTPS/TLS Arguments
| Parameter | Type | Default | Description |
|---|---|---|---|
| verify | bool | True | Validate the ClickHouse server TLS/SSL certificate (hostname, expiration, etc.) if using HTTPS/TLS. |
| ca_cert | str | None | If verify=True, the file path to Certificate Authority root to validate ClickHouse server certificate, in .pem format. Ignored if verify is False. This is not necessary if the ClickHouse server certificate is a globally trusted root as verified by the operating system. |
| client_cert | str | None | File path to a TLS Client certificate in .pem format (for mutual TLS authentication). The file should contain a full certificate chain, including any intermediate certificates. |
| client_cert_key | str | None | File path to the private key for the Client Certificate. Required if the private key is not included the Client Certificate key file. |
| server_host_name | str | None | The ClickHouse server hostname as identified by the CN or SNI of its TLS certificate. Set this to avoid SSL errors when connecting through a proxy or tunnel with a different hostname |
Settings Argument
Finally, the settings argument to get_client is used to pass additional ClickHouse settings to the server for each
client request. Note that in most cases, users with readonly=1 access cannot alter settings sent with a query, so
ClickHouse Connect will drop such settings in the final request and log a warning. The following settings apply only to
HTTP queries/sessions used by ClickHouse Connect, and are not documented as general ClickHouse settings.
| Setting | Description |
|---|---|
| buffer_size | Buffer size (in bytes) used by ClickHouse Server before writing to the HTTP channel. |
| session_id | A unique session id to associate related queries on the server. Required for temporary tables. |
| compress | Whether the ClickHouse server should compress the POST response data. This setting should only be used for "raw" queries. |
| decompress | Whether the data sent to ClickHouse server must be decompressed. This setting is should only be used for "raw" inserts. |
| quota_key | The quota key associated with this requests. See the ClickHouse server documentation on quotas. |
| session_check | Used to check the session status. |
| session_timeout | Number of seconds of inactivity before the identified by the session id will timeout and no longer be considered valid. Defaults to 60 seconds. |
| wait_end_of_query | Buffers the entire response on the ClickHouse server. This setting is required to return summary information, and is set for automatically on non-streaming queries. |
For other ClickHouse settings that can be sent with each query, see the ClickHouse documentation.
Client Creation Examples
- Without any parameters, a ClickHouse Connect client will connect to the default HTTP port on
localhostwith the default user and no password:
import clickhouse_connect
client = clickhouse_connect.get_client()
client.server_version
Out[2]: '22.10.1.98'
- Connecting to a secure (https) external ClickHouse server
import clickhouse_connect
client = clickhouse_connect.get_client(host='play.clickhouse.com', secure=True, port=443, user='play', password='clickhouse')
client.command('SELECT timezone()')
Out[2]: 'Etc/UTC'
- Connecting with a session id and other custom connection parameters and ClickHouse settings.
import clickhouse_connect
client = clickhouse_connect.get_client(host='play.clickhouse.com',
user='play',
password='clickhouse',
port=443,
session_id='example_session_1',
connect_timeout=15,
database='github',
settings={'distributed_ddl_task_timeout':300})
client.database
Out[2]: 'github'
Common Method Arguments
Several client methods use one or both of the common parameters and settings arguments. These keyword
arguments are described below.
Parameters Argument
ClickHouse Connect Client query* and command methods accept an optional parameters keyword argument used for
binding Python expressions to a ClickHouse value expression. Two sorts of binding are available.
Server Side Binding
ClickHouse supports server side binding
for most query values, where the bound value is sent separate from the query as an HTTP query parameter. ClickHouse
Connect will add the appropriate query parameters if it detects a binding expression of the form
{<name>:<datatype>}. For server side binding, the parameters argument should be a Python dictionary.
- Server Side Binding with Python Dictionary, DateTime value and string value
import datetime
my_date = datetime.datetime(2022, 10, 01, 15, 20, 5)
parameters = {'table': 'my_table', 'v1': my_date, 'v2': "a string with a single quote'"}
client.query('SELECT * FROM {table:Identifier} WHERE date >= {v1:DateTime} AND string ILIKE {v2:String}', parameters=parameters)
# Generates the following query on the server
# SELECT * FROM my_table WHERE date >= '2022-10-01 15:20:05' AND string ILIKE 'a string with a single quote\''
IMPORTANT -- Server side binding is only supported (by the ClickHouse server) for SELECT queries. It does not work for
ALTER, DELETE, INSERT, or other types of queries. This may change in the future, see https://github.com/ClickHouse/ClickHouse/issues/42092.
Client Side Binding
ClickHouse Connect also supports client side parameter binding which can allow more flexibility in generating templated
SQL queries. For client side binding, the parameters argument should be a dictionary or a sequence. Client side
binding uses the Python "printf" style string
formatting for parameter substitution.
Note that unlike server side binding, client side binding doesn't work for database identifiers such as database, table, or column names, since Python style formatting can't distinguish between the different types of strings, and they need to be formatted differently (backticks or double quotes for database identifiers, single quotes for data values).
- Example with Python Dictionary, DateTime value and string escaping
import datetime
my_date = datetime.datetime(2022, 10, 01, 15, 20, 5)
parameters = {'v1': my_date, 'v2': "a string with a single quote'"}
client.query('SELECT * FROM some_table WHERE date >= %(v1)s AND string ILIKE %(v2)s', parameters=parameters)
# Generates the following query:
# SELECT * FROM some_table WHERE date >= '2022-10-01 15:20:05' AND string ILIKE 'a string with a single quote\''
- Example with Python Sequence (Tuple), Float64, and IPv4Address
import ipaddress
parameters = (35200.44, ipaddress.IPv4Address(0x443d04fe))
client.query('SELECT * FROM some_table WHERE metric >= %s AND ip_address = %s', parameters=parameters)
# Generates the following query:
# SELECT * FROM some_table WHERE metric >= 35200.44 AND ip_address = '68.61.4.254''
Settings Argument
All the key ClickHouse Connect Client "insert" and "select" methods accept an optional settings keyword argument to
pass ClickHouse server user settings for the included SQL statement. The settings argument should be a
dictionary. Each item should be a ClickHouse setting name and its associated value. Note that values will be
converted to strings when sent to the server as query parameters.
As with client level settings, ClickHouse Connect will drop any settings that the server marks as readonly=1, with
an associated log message. Settings that apply only to queries via the ClickHouse HTTP interface are always valid. Those
settings are described under the get_client API.
Example of using ClickHouse settings:
settings = {'merge_tree_min_rows_for_concurrent_read': 65535,
'session_id': 'session_1234',
'use_skip_indexes': False}
client.query("SELECT event_type, sum(timeout) FROM event_errors WHERE event_time > '2022-08-01'", settings=settings)
Client command Method
Use the Client.command method to send SQL queries to the ClickHouse Server that do not normally return data or returns
a single primitive or array value rather than a full dataset. This method takes the following parameters:
| Parameter | Type | Default | Description |
|---|---|---|---|
| cmd | str | Required | A ClickHouse SQL statement that returns a single value or a single row of values. |
| parameters | dict or iterable | None | See parameters description. |
| data | str or bytes | None | Optional data to include with the command as the POST body. |
| settings | dict | None | See settings description. |
| use_database | bool | True | Use the client database (specified when creating the client). False means the command will use the default ClickHouse Server database for the connected user. |
| external_data | ExternalData | None | An ExternalData object containing file or binary data to use with the query. See Advanced Queries (External Data) |
- command can be used for DDL statements. If the SQL "command" does not return data, a "query summary"
dictionary is returned instead. This dictionary encapsulates the ClickHouse X-ClickHouse-Summary and
X-ClickHouse-Query-Id headers, including the key/value pairs
written_rows,written_bytes, andquery_id.
client.command('CREATE TABLE test_command (col_1 String, col_2 DateTime) Engine MergeTree ORDER BY tuple()')
client.command('SHOW CREATE TABLE test_command')
Out[6]: 'CREATE TABLE default.test_command\\n(\\n `col_1` String,\\n `col_2` DateTime\\n)\\nENGINE = MergeTree\\nORDER BY tuple()\\nSETTINGS index_granularity = 8192'
- command can also be used for simple queries that return only a single row
result = client.command('SELECT count() FROM system.tables')
result
Out[7]: 110
Client query Method
The Client.query method is the primary way to retrieve a single "batch" dataset from the ClickHouse Server. It
utilizes the Native ClickHouse format over HTTP to transmit large datasets (up to approximately one million rows)
efficiently. This method takes the following parameters.
| Parameter | Type | Default | Description |
|---|---|---|---|
| query | str | Required | The ClickHouse SQL SELECT or DESCRIBE query. |
| parameters | dict or iterable | None | See parameters description. |
| settings | dict | None | See settings description. |
| query_formats | dict | None | Datatype formatting specification for result values. See Advanced Usage (Read Formats) |
| column_formats | dict | None | Datatype formatting per column. See Advanced Usage (Read Formats) |
| encoding | str | None | Encoding used to encode ClickHouse String columns into Python strings. Python defaults to UTF-8 if not set. |
| use_none | bool | True | Use Python None type for ClickHouse nulls. If False, use a datatype default (such as 0) for ClickHouse nulls. Note - defaults to False for numpy/Pandas for performance reasons. |
| column_oriented | bool | False | Return the results as a sequence of columns rather than a sequence of rows. Helpful for transforming Python data to other column oriented data formats. |
| query_tz | str | None | A timezone name from the zoneinfo database. This timezone will be applied to all datetime or Pandas Timestamp objects returned by the query. |
| column_tzs | dict | None | A dictionary of column name to timezone name. Like query_tz, but allows specifying different timezones for different columns. |
| use_extended_dtypes | bool | True | Use Pandas extended dtypes (like StringArray), and pandas.NA and pandas.NaT for ClickHouse NULL values. Apples only to query_df and query_df_stream methods. |
| external_data | ExternalData | None | An ExternalData object containing file or binary data to use with the query. See Advanced Queries (External Data) |
| context | QueryContext | None | A reusable QueryContext object can be used to encapsulate the above method arguments. See Advanced Queries (QueryContexts) |
The QueryResult Object
The base query method returns a QueryResult object with the following public properties:
result_rows-- A matrix of the data returned in the form of a Sequence of rows, with each row element being a sequence of column values.result_columns-- A matrix of the data returned in the form of a Sequence of columns, with each column element being a sequence of the row values for that columncolumn_names-- A tuple of strings representing the column names in theresult_setcolumn_types-- A tuple of ClickHouseType instances representing the ClickHouse data type for each column in theresult_columnsquery_id-- The ClickHouse query_id (useful for examining the query in thesystem.query_logtable)summary-- Any data returned by theX-ClickHouse-SummaryHTTP response headerfirst_item-- A convenience property for retrieving the first row of the response as a dictionary (keys are column names)first_row-- A convenience property to return the first row of the resultcolumn_block_stream-- A generator of query results in column oriented format. This property should not be referenced directly (see below).row_block_stream-- A generator of query results in row oriented format. This property should not be referenced directly (see below).rows_stream-- A generator of query results that yields a single row per invocation. This property should not be referenced directly (see below).summary-- As described under thecommandmethod, a dictionary of summary information returned by ClickHouse
The *_stream properties return a Python Context that can be used as an iterator for the returned data. They should
only be accessed indirectly using the Client *_stream methods.
The complete details of streaming query results (using StreamContext objects) are outlined in Advanced Queries (Streaming Queries).
Consuming query results with Numpy, Pandas or Arrow
There are three specialized versions of the main query method:
query_np-- This version returns a Numpy Array instead a ClickHouse Connect QueryResult.query_df-- This version returns a Pandas Dataframe instead of a ClickHouse Connect QueryResult.query_arrow-- This version returns a PyArrow Table. It utilizes the ClickHouseArrowformat directly, so it only accepts three arguments in common with the mainquery method:query,parameters, andsettings. In addition, there is additional argumentuse_stringswhich determines whether the Arrow Table will render ClickHouse String types as strings (if True) or bytes (if False).
Client Streaming Query Methods
The ClickHouse Connect Client provides multiple methods for retrieving data as a stream (implemented as a Python generator):
query_column_block_stream-- Returns query data in blocks as a sequence of columns using native Python objectquery_row_block_stream-- Returns query data as a block of rows using native Python objectquery_rows_stream-- Returns query data as a sequence of rows using native Python objectquery_np_stream-- Returns each ClickHouse block of query data as a Numpy arrayquery_df_stream-- Returns each ClickHouse Block of query data as a Pandas Dataframequery_arrow_stream-- Returns query data in PyArrow RecordBlocks
Each of these methods returns a ContextStream object that must be opened via a with statement to start consuming the
stream. See Advanced Queries (Streaming Queries) for details and examples.
Client insert Method
For the common use case of inserting multiple records into ClickHouse, there is the Client.insert method. It takes the
following parameters:
| Parameter | Type | Default | Description |
|---|---|---|---|
| table | str | Required | The ClickHouse table to insert into. The full table name (including database) is permitted. |
| data | Sequence of Sequences | Required | The matrix of data to insert, either a Sequence of rows, each of which is a sequence of column values, or a Sequence of columns, each of which is a sequence of row values. |
| column_names | Sequence of str, or str | '*' | A list of column_names for the data matrix. If '*' is used instead, ClickHouse Connect will execute a "pre-query" to retrieve all of the column names for the table. |
| database | str | '' | The target database of the insert. If not specified, the database for the client will be assumed. |
| column_types | Sequence of ClickHouseType | None | A list of ClickHouseType instances. If neither column_types or column_type_names is specified, ClickHouse Connect will execute a "pre-query" to retrieve all the column types for the table. |
| column_type_names | Sequence of ClickHouse type names | None | A list of ClickHouse datatype names. If neither column_types or column_type_names is specified, ClickHouse Connect will execute a "pre-query" to retrieve all the column types for the table. |
| column_oriented | bool | False | If True, the data argument is assume to be a Sequence of columns (and no "pivot" will be necessary to insert the data). Otherwise data is interpreted as a Sequence of rows. |
| settings | dict | None | See settings description. |
| insert_context | InsertContext | None | A reusable InsertContext object can be used to encapsulate the above method arguments. See Advanced Inserts (InsertContexts) |
This method returns a "query summary" dictionary as described under the "command" method. An exception will be raised if the insert fails for any reason.
There are two specialized versions of the main insert method:
insert_df-- Instead of Python Sequence of Sequencesdataargument, the second parameter of this method requires adfargument that must be a Pandas Dataframe instance. ClickHouse Connect automatically processes the Dataframe as a column oriented datasource, so thecolumn_orientedparameter is not required or available.insert_arrow-- Instead of a Python Sequence of Sequencesdataargument, this method requires anarrow_table. ClickHouse Connect passes the Arrow table unmodified to the ClickHouse server for processing, so only thedatabaseandsettingsarguments are available in addition totableandarrow_table.
Note: A Numpy array is a valid Sequence of Sequences and can be used as the data argument to the main insert
method, so a specialized method is not required.
File Inserts
The clickhouse_connect.driver.tools includes the insert_file method that allows inserting data directly from the
file system into an existing ClickHouse table. Parsing is delegated to the ClickHouse server. insert_file accepts
the following parameters:
| Parameter | Type | Default | Description |
|---|---|---|---|
| client | Client | Required | The driver.Client used to perform the insert |
| table | str | Required | The ClickHouse table to insert into. The full table name (including database) is permitted. |
| file_path | str | Required | The native file system path to the data file |
| fmt | str | CSV, CSVWithNames | The ClickHouse Input Format of the file. CSVWithNames is assumed if column_names is not provided |
| column_names | Sequence of str | None | A list of column_names in the data file. Not required for formats that include column names |
| database | str | None | Database of the table. Ignored if the table is fully qualified. If not specified, the insert will use the client database |
| settings | dict | None | See settings description. |
| compression | str | None | A recognized ClickHouse compression type (zstd, lz4, gzip) used for the Content-Encoding HTTP header |
For files with inconsistent data or date/time values in an unusual format, settings that apply to data imports (such as
input_format_allow_errors_num and input_format_allow_errors_num) are recognized for this method.
import clickhouse_connect
from clickhouse_connect.driver.tools import insert_file
client = clickhouse_connect.get_client()
insert_file(client, 'example_table', 'my_data.csv',
settings={'input_format_allow_errors_ratio': .2,
'input_format_allow_errors_num': 5})
Saving query results as files
You can stream files directly from ClickHouse to the local file system using the raw_stream method. For example, if you'd like to save the results of a query to a CSV file, you could use the following code snippet:
import clickhouse_connect
if __name__ == '__main__':
client = clickhouse_connect.get_client()
query = 'SELECT number, toString(number) AS number_as_str FROM system.numbers LIMIT 5'
fmt = 'CSVWithNames' # or CSV, or CSVWithNamesAndTypes, or TabSeparated, etc.
stream = client.raw_stream(query=query, fmt=fmt)
with open("output.csv", "wb") as f:
for chunk in stream:
f.write(chunk)
The code above yields an output.csv file with the following content:
"number","number_as_str"
0,"0"
1,"1"
2,"2"
3,"3"
4,"4"
Similarly, you could save data in TabSeparated and other formats. See Formats for Input and Output Data for an overview of all available format options.
Raw API
For use cases which do not require transformation between ClickHouse data and native or third party data types and structures, the ClickHouse Connect client provides two methods for direct usage of the ClickHouse connection.
Client raw_query Method
The Client.raw_query method allows direct usage of the ClickHouse HTTP query interface using the client connection.
The return value is an unprocessed bytes object. It offers a convenient wrapper with parameter binding,
error handling, retries, and settings management using a minimal interface:
| Parameter | Type | Default | Description |
|---|---|---|---|
| query | str | Required | Any valid ClickHouse query |
| parameters | dict or iterable | None | See parameters description. |
| settings | dict | None | See settings description. |
| fmt | str | None | ClickHouse Output Format for the resulting bytes. (ClickHouse uses TSV if not specified) |
| use_database | bool | True | Use the clickhouse-connect Client assigned database for the query context |
| external_data | ExternalData | None | An ExternalData object containing file or binary data to use with the query. See Advanced Queries (External Data) |
It is the caller's responsibility to handle the resulting bytes object. Note that the Client.query_arrow is just a
thin wrapper around this method using the ClickHouse Arrow output format.
Client raw_stream Method
The Client.raw_stream method has the same API as the raw_query method, but returns an io.IOBase object which can be used
as a generator/stream source of bytes objects. It is currently utilized by the query_arrow_stream method.
Client raw_insert Method
The Client.raw_insert method allows direct inserts of bytes objects or bytes object generators using the client
connection. Because it does no processing of the insert payload, it is highly performant. The method provides options
to specify settings and insert format:
| Parameter | Type | Default | Description |
|---|---|---|---|
| table | str | Required | Either the simple or database qualified table name |
| column_names | Sequence[str] | None | Column names for the insert block. Required if the fmt parameter does not include names |
| insert_block | str, bytes, Generator[bytes], BinaryIO | Required | Data to insert. Strings will be encoding with the client encoding. |
| settings | dict | None | See settings description. |
| fmt | str | None | ClickHouse Input Format of the insert_block bytes. (ClickHouse uses TSV if not specified) |
It is the caller's responsibility that the insert_block is in the specified format and uses the specified compression
method. ClickHouse Connect uses these raw inserts for file uploads and PyArrow Tables, delegating parsing to the ClickHouse server.
Multithreaded, Multiprocess, and Async/Event Driven Use Cases
ClickHouse Connect works well in multithreaded, multiprocess, and event loop driven/asynchronous applications. All query and insert processing occurs within a single thread, so operations are generally thread safe. (Parallel processing of some operations at a low level is a possible future enhancement to overcome the performance penalty of a single thread, but even in that case thread safety will be maintained).
Because each query or insert executes maintains state in its own QueryContext or InsertContext object, respectively, these helper objects are not thread safe, and they should not be shared between multiple processing streams. See the additional discussion about context objects in following sections.
Additionally, in an application that has two or more queries and/or inserts "in flight" at the same time, there are two further considerations to keep in mind. The first is the ClickHouse "session" associated with the query/insert, and the second is the HTTP connection pool used by ClickHouse Connect Client instances.
Managing ClickHouse Session Ids
Each ClickHouse query occurs within the context of a ClickHouse "session". Sessions are currently used for two purposes:
- To associate specific ClickHouse settings with multiple queries (see the
user settings). The ClickHouse
SETcommand is used to change the settings for the scope of a user session. - To track temporary tables.
By default, each query executed with a ClickHouse Connect Client instance uses the same session id to enable this
session functionality. That is, SET statements and temporary table work as expected when using a single ClickHouse
client. However, by design the ClickHouse server does not allow concurrent queries within the same session.
As a result, there are two options for a ClickHouse Connect application that will execute concurrent queries.
- Create a separate
Clientinstance for each thread of execution (thread, process, or event handler) that will have its own session id. This is generally the best approach, as it preserves the session state for each client. - Use a unique session id for each query. This avoids the concurrent session problem in circumstances where
temporary tables or shared session settings are not required. (Shared settings can also be provided
when creating the client, but these are sent with each request and not associated with a session). The unique
session_id can be added to the
settingsdictionary for each request, or you can disable theautogenerate_session_idcommon setting:
from clickhouse_connect import common
common.set_setting('autogenerate_session_id', False) # This should always be set before creating a client
client = clickhouse_connect.get_client(host='somehost.com', user='dbuser', password=1234)
In this case ClickHouse Connect will not send any session id, and a random session id will be generated by the ClickHouse server. Again, temporary tables and session level settings will not be available.
Customizing the HTTP Connection Pool
ClickHouse Connect uses urllib3 connection pools to handle the underlying HTTP connection to the server. By default,
all client instances share the same connection pool, which is sufficient for the majority of use cases. This default
pool maintains up to 8 HTTP Keep Alive connections to each ClickHouse server used by the application.
For large multithreaded applications, separate connection pools may be appropriate. Customized connection pools
can be provided as the pool_mgr keyword argument to the main clickhouse_connect.get_client function:
import clickhouse_connect
from clickhouse_connect.driver import httputil
big_pool_mgr = httputil.get_pool_manager(maxsize=16, num_pools=12)
client1 = clickhouse_connect.get_client(pool_mgr=big_pool_mgr)
client2 = clickhouse_connect.get_client(pool_mgr=big_pool_mgr)
As demonstrated by the above example, clients can share a pool manager, or a separate pool manager can be created for each client. For more details on the options available when creating a PoolManager, see the urllib3 documentation.
Querying Data with ClickHouse Connect: Advanced Usage
QueryContexts
ClickHouse Connect executes standard queries within a QueryContext. The QueryContext contains the key structures that are used to build queries against the ClickHouse database, and the configuration used to process the result into a QueryResult or other response data structure. That includes the query itself, parameters, settings, read formats, and other properties.
A QueryContext can be acquired using the client create_query_context method. This method takes the same parameters
as the core query method. This query context can then be passed to the query, query_df, or query_np methods as the context
keyword argument instead of any or all of the other arguments to those methods. Note that additional arguments specified for the
method call will override any properties of QueryContext.
The clearest use case for a QueryContext is to send the same query with different binding parameter values. All parameter values can
be updated by calling the QueryContext.set_parameters method with a dictionary, or any single value can be updated by calling
QueryContext.set_parameter with the desired key, value pair.
client.create_query_context(query='SELECT value1, value2 FROM data_table WHERE key = {k:Int32}',
parameters={'k': 2},
column_oriented=True)
result = client.query(context=qc)
assert result.result_set[1][0] == 'second_value2'
qc.set_parameter('k', 1)
result = test_client.query(context=qc)
assert result.result_set[1][0] == 'first_value2'
Note that QueryContexts are not thread safe, but a copy can be obtained in a multithreaded environment by calling the
QueryContext.updated_copy method.
Streaming Queries
Data Blocks
ClickHouse Connect processes all data from the primary query method as a stream of blocks received from the ClickHouse server.
These blocks are transmitted in the custom "Native" format to and from ClickHouse. A "block" is simply a sequence of columns of binary data,
where each column contains an equal number of data values of the specified data type. (As a columnar database, ClickHouse stores this data
in a similar form.) The size of a block returned from a query is governed by two user settings that can be set at several levels
(user profile, user, session, or query). They are:
- max_block_size -- Limit on the size of the block in rows. Default 65536.
- preferred_block_size_bytes -- Soft limit on the size of the block in bytes. Default 1,000,0000.
Regardless of the preferred_block_size_setting, each block will never be more than max_block_size rows. Depending on the
type of query, the actual blocks returned can be of any size. For example, queries to a distributed table covering many shards
may contain smaller blocks retrieved directly from each shard.
When using one of the Client query_*_stream methods, results are returned on a block by block basis. ClickHouse Connect only
loads a single block at a time. This allows processing large amounts of data without the need to load all of a large result
set into memory. Note the application should be prepared to process any number of blocks and the exact size of each block
cannot be controlled.
StreamContexts
Each of the query_*_stream methods (like query_row_block_stream) returns a ClickHouse StreamContext object, which
is a combined Python context/generator. This is the basic usage:
with client.query_row_block_stream('SELECT pickup, dropoff, pickup_longitude, pickup_latitude FROM taxi_trips') as stream:
for block in stream:
for row in block:
<do something with each row of Python trip data>
Note that trying to use a StreamContext without a with statement will raise an error. The use of a Python context ensures
that the stream (in this case, a streaming HTTP response) will be properly closed even if not all the data is consumed and/or
an exception is raised during processing. Also, StreamContexts can only be used once to consume the stream. Trying to use a StreamContext
after it has exited will produce a StreamClosedError.
You can use the source property of the StreamContext to access the parent QueryResult object, which includes column names
and types.
Stream Types
The query_column_block_stream method returns the block as a sequence of column data stored as native Python data types. Using
the above taxi_trips queries, the data returned will be a list where each element of the list is another list (or tuple)
containing all the data for the associated column. So block[0] would be a tuple containing nothing but strings. Column
oriented formats are most used for doing aggregate operations for all the values in a column, like adding up total fairs.
The query_row_block_stream method returns the block as a sequence of rows like a traditional relational database. For taxi
trips, the data returned will be a list where each element of the list is another list representing a row of data. So block[0]
would contain all the fields (in order) for the first taxi trip , block[1] would contain a row for all the fields in
the second taxi trip, and so on. Row oriented results are normally used for display or transformation processes.
The query_row_stream is a convenience method that automatically moves to the next block when iterating through the stream.
Otherwise, it is identical to query_row_block_stream.
The query_np_stream method return each block as a two-dimensional Numpy Array. Internally Numpy arrays are (usually) stored as columns,
so no distinct row or column methods are needed. The "shape" of the numpy array will be expressed as (columns, rows). The Numpy
library provides many methods of manipulating numpy arrays. Note that if all columns in the query share the same Numpy dtype,
the returned numpy array will only have one dtype as well, and can be reshaped/rotated without actually changing its internal structure.
The query_df_stream method returns each ClickHouse Block as a two-dimensional Pandas Dataframe. Here's an example
which shows that the StreamContext object can be used as a context in a deferred fashion (but only once).
Finally, the query_arrow_stream method returns a ClickHouse ArrowStream formatted result as a pyarrow.ipc.RecordBatchStreamReader
wrapped in StreamContext. Each iteration of the stream returns PyArrow RecordBlock.
df_stream = client.query_df_stream('SELECT * FROM hits')
column_names = df_stream.source.column_names
with df_stream:
for df in df_stream:
<do something with the pandas DataFrame>
Read Formats
Read formats control the data types of values returned from the client query, query_np, and query_df methods. (The raw_query
and query_arrow do not modify incoming data from ClickHouse, so format control does not apply.) For example, if the read format
for a UUID is changed from the default native format to the alternative string format, a ClickHouse query of UUID column will be
returned as string values (using the standard 8-4-4-4-12 RFC 1422 format) instead of Python UUID objects.
The "data type" argument for any formatting function can include wildcards. The format is a single lower case string.
Read formats can be set at several levels:
- Globally, using the methods defined in the
clickhouse_connect.datatypes.formatpackage. This will control the format of the configured datatype for all queries.
from clickhouse_connect.datatypes.format import set_read_format
# Return both IPv6 and IPv4 values as strings
set_read_format('IPv*', 'string')
# Return all Date types as the underlying epoch second or epoch day
set_read_format('Date*', 'int')
- For an entire query, using the optional
query_formatsdictionary argument. In that case any column (or subcolumn) of the specified data types(s) will use the configured format.
# Return any UUID column as a string
client.query('SELECT user_id, user_uuid, device_uuid from users', query_formats={'UUID': 'string'})
- For the values in a specific column, using the optional
column_formatsdictionary argument. The key is the column named as return by ClickHouse, and format for the data column or a second level "format" dictionary of a ClickHouse type name and a value of query formats. This secondary dictionary can be used for nested column types such as Tuples or Maps.
# Return IPv6 values in the `dev_address` column as strings
client.query('SELECT device_id, dev_address, gw_address from devices', column_formats={'dev_address', 'string'})
Read Format Options (Python Types)
| ClickHouse Type | Native Python Type | Read Formats | Comments |
|---|---|---|---|
| Int[8-64], UInt[8-32] | int | - | |
| UInt64 | int | signed | Superset does not currently handle large unsigned UInt64 values |
| [U]Int[128,256] | int | string | Pandas and Numpy int values are 64 bits maximum, so these can be returned as strings |
| Float32 | float | - | All Python floats are 64 bits internally |
| Float64 | float | - | |
| Decimal | decimal.Decimal | - | |
| String | string | bytes | ClickHouse String columns have no inherent encoding, so they are also used for variable length binary data |
| FixedString | bytes | string | FixedStrings are fixed size byte arrays, but sometimes are treated as Python strings |
| Enum[8,16] | string | string, int | Python enums don't accept empty strings, so all enums are rendered as either strings or the underlying int value. |
| Date | datetime.date | int | ClickHouse stores Dates as days since 01/01/1970. This value is available as an int |
| Date32 | datetime.date | int | Same as Date, but for a wider range of dates |
| DateTime | datetime.datetime | int | ClickHouse stores DateTime in epoch seconds. This value is available as an int |
| DateTime64 | datetime.datetime | int | Python datetime.datetime is limited to microsecond precision. The raw 64 bit int value is available |
| IPv4 | ipaddress.IPv4Address | string | IP addresses can be read as strings and properly formatted strings can be inserted as IP addresses |
| IPv6 | ipaddress.IPv6Address | string | IP addresses can be read as strings and properly formatted can be inserted as IP addresses |
| Tuple | dict or tuple | tuple, json | Named tuples returned as dictionaries by default. Named tuples can also be returned as JSON strings |
| Map | dict | - | |
| Nested | Sequence[dict] | - | |
| UUID | uuid.UUID | string | UUIDs can be read as strings formatted as per RFC 4122 |
External Data
ClickHouse queries can accept external data in any ClickHouse format. This binary data is sent along with the query string to be used to process the data. Details of
the External Data feature are here. The client query* methods accept an optional external_data parameter
to take advantage of this feature. The value for the external_data parameter should be a clickhouse_connect.driver.external.ExternalData object. The constructor
for that object accepts the follow arguments:
| Name | Type | Description |
|---|---|---|
| file_path | str | Path to a file on the local system path to read the external data from. Either file_path or data is required |
| file_name | str | The name of the external data "file". If not provided, will be determined from the file_path (without extensions) |
| data | bytes | The external data in binary form (instead of being read from a file). Either data or file_path is required |
| fmt | str | The ClickHouse Input Format of the data. Defaults to TSV |
| types | str or seq of str | A list of column data types in the external data. If a string, types should be separated by commas. Either types or structure is required |
| structure | str or seq of str | A list of column name + data type in the data (see examples). Either structure or types is required |
| mime_type | str | Optional MIME type of the file data. Currently ClickHouse ignores this HTTP subheader |
To send a query with an external CSV file containing "movie" data, and combine that data with an directors table already present on the ClickHouse server:
import clickhouse_connect
from clickhouse_connect.driver.external import ExternalData
client = clickhouse_connect.get_client()
ext_data = ExternalData(file_path='/data/movies.csv',
fmt='CSV',
structure=['movie String', 'year UInt16', 'rating Decimal32(3)', 'director String'])
result = client.query('SELECT name, avg(rating) FROM directors INNER JOIN movies ON directors.name = movies.director GROUP BY directors.name',
external_data=ext_data).result_rows
Additional external data files can be added to the initial ExternalData object using the add_file method, which takes the same parameters
as the constructor. For HTTP, all external data is transmitted as part of a multi-part/form-data file upload.
Time Zones
There are multiple mechanisms for applying a time zone to ClickHouse DateTime and DateTime64 values. Internally, the ClickHouse server always stores any DateTime or DateTime64 object as a time zone naive number representing seconds since the epoch, 1970-01-01 00:00:00 UTC time. For DateTime64 values, the representation can be milliseconds, microseconds, or nanoseconds since the epoch, depending on precision. As a result, the application of any time zone information always occurs on the client side. Note that this involves meaningful extra calculation, so in performance critical applications it is recommended to treat DateTime types as epoch timestamps except for user display and conversion (Pandas Timestamps, for example, are always a 64-bit integer representing epoch nanoseconds to improve performance).
When using time zone aware data types in queries - in particular the Python datetime.datetime object -- clickhouse-connect applies a client side time zone using the following
precedence rules:
- If the query method parameter
client_tzsis specified for the query, the specific column time zone is applied - If the ClickHouse column has timezone metadata (i.e., it is a type like DateTime64(3, 'America/Denver')), the ClickHouse column timezone is applied. (Note this timezone metadata is not available to clickhouse-connect for DateTime columns previous to ClickHouse version 23.2)
- If the query method parameter
query_tzis specified for the query, the "query timezone" is applied. - If a timezone setting is applied to the query or session, that timezone is applied. (This functionality is not yet released in the ClickHouse Server)
- Finally, if the client
apply_server_timezoneparameter has been set to True (the default), the ClickHouse server timezone is applied.
Note that if the applied timezone based on these rules is UTC, clickhouse-connect will always return a time zone naive Python datetime.datetime object. Additional timezone
information can then be added to this timezone naive object by the application code if desired.
Inserting Data with ClickHouse Connect: Advanced Usage
InsertContexts
ClickHouse Connect executes all inserts within an InsertContext. The InsertContext includes all the values sent as arguments to
the client insert method. In addition, when an InsertContext is originally constructed, ClickHouse Connect retrieves the data types
for the insert columns required for efficient Native format inserts. By reusing the InsertContext for multiple inserts, this "pre-query"
is avoided and inserts are executed more quickly and efficiently.
An InsertContext can be acquired using the client create_insert_context method. The method takes the same arguments as
the insert function. Note that only the data property of InsertContexts should be modified for reuse. This is consistent
with its intended purpose of providing a reusable object for repeated inserts of new data to the same table.
test_data = [[1, 'v1', 'v2'], [2, 'v3', 'v4']]
ic = test_client.create_insert_context(table='test_table', data='test_data')
client.insert(context=ic)
assert client.command('SELECT count() FROM test_table') == 2
new_data = [[3, 'v5', 'v6'], [4, 'v7', 'v8']]
ic.data = new_data
client.insert(context=ic)
qr = test_client.query('SELECT * FROM test_table ORDER BY key DESC')
assert qr.row_count == 4
assert qr[0][0] == 4
InsertContexts include mutable state that is updated during the insert process, so they are not thread safe.
Write Formats
Write formats are currently implemented for limited number of types. In most cases ClickHouse Connect will attempt to automatically determine the correct write format for a column by checking the type of the first (non-null) data value. For example, if inserting into a DateTime column, and the first insert value of the column is a Python integer, ClickHouse Connect will directly insert the integer value under the assumption that it's actually an epoch second.
In most cases, it is unnecessary to override the write format for a data type, but the associated methods in the
clickhouse_connect.datatypes.format package can be used to do so at a global level.
Write Format Options
| ClickHouse Type | Native Python Type | Write Formats | Comments |
|---|---|---|---|
| Int[8-64], UInt[8-32] | int | - | |
| UInt64 | int | ||
| [U]Int[128,256] | int | ||
| Float32 | float | ||
| Float64 | float | ||
| Decimal | decimal.Decimal | ||
| String | string | ||
| FixedString | bytes | string | If inserted as a string, additional bytes will be set to zeros |
| Enum[8,16] | string | ||
| Date | datetime.date | int | ClickHouse stores Dates as days since 01/01/1970. int types will be assumed to be this "epoch date" value |
| Date32 | datetime.date | int | Same as Date, but for a wider range of dates |
| DateTime | datetime.datetime | int | ClickHouse stores DateTime in epoch seconds. int types will be assumed to be this "epoch second" value |
| DateTime64 | datetime.datetime | int | Python datetime.datetime is limited to microsecond precision. The raw 64 bit int value is available |
| IPv4 | ipaddress.IPv4Address | string | Properly formatted strings can be inserted as IPv4 addresses |
| IPv6 | ipaddress.IPv6Address | string | Properly formatted strings can be inserted as IPv6 addresses |
| Tuple | dict or tuple | ||
| Map | dict | ||
| Nested | Sequence[dict] | ||
| JSON/Object('json') | dict | string | Either dictionaries or JSON strings can be inserted into JSON Columns. |
| UUID | uuid.UUID | string | Properly formatted strings can be inserted as ClickHouse UUIDs |
Additional Options
ClickHouse Connect provides a number of additional options for advanced use cases
Global Settings
There are a small number of settings that control ClickHouse Connect behavior globally. They are accessed from the top
level common package:
from clickhouse_connect import common
common.set_setting('autogenerate_session_id', False)
common.get_setting('invalid_setting_action')
'drop'
These common settings autogenerate_session_id, product_name, and readonly should always be modified before
creating a client with the clickhouse_connect.get_client method. Changing these settings after client creation does
not affect the behavior of existing clients.
Eight global settings are currently defined:
| Setting Name | Default | Options | Description |
|---|---|---|---|
| autogenerate_session_id | True | True, False | Autogenerate a new UUID(1) session id (if not provided) for each client session. If no session id is provided (either at the client or query level, ClickHouse will generate random internal id for each query |
| invalid_setting_action | 'error' | 'drop', 'send', 'error' | Action to take when an invalid or readonly setting is provided (either for the client session or query). If drop, the setting will be ignored, if send, the setting will be sent to ClickHouse, if error a client side ProgrammingError will be raised |
| dict_parameter_format | 'json' | 'json', 'map' | This controls whether parameterized queries convert a Python dictionary to JSON or ClickHouse Map syntax. json should be used for inserts into JSON columns, map for ClickHouse Map columns |
| product_name | A string that is passed with the query to clickhouse for tracking the app using ClickHouse Connect. Should be in the form <product name;&gl/<product version> | ||
| max_connection_age | 600 | Maximum seconds that an HTTP Keep Alive connection will be kept open/reused. This prevents bunching of connections against a single ClickHouse node behind a load balancer/proxy. Defaults to 10 minutes. | |
| readonly | 0 | 0, 1 | Implied "read_only" ClickHouse settings for versions prior to 19.17. Can be set to match the ClickHouse "read_only" value for settings to allow operation with very old ClickHouse versions |
| use_protocol_version | True | True, False | Use the client protocol version. This is needed for DateTime timezone columns but breaks with the current version of chproxy |
| max_error_size | 1024 | Maximum number of characters that will be returned in a client error messages. Use 0 for this setting to get the full ClickHouse error message. Defaults to 1024 characters. |
Compression
ClickHouse Connect supports lz4, zstd, brotli, and gzip compression for both query results and inserts. Always keep in mind that using compression usually involves a tradeoff between network bandwidth/transfer speed against CPU usage (both on the client and the server.)
To receive compressed data, the ClickHouse server enable_http_compression must be set to 1, or the user must have
permission to change the setting on a "per query" basis.
Compression is controlled by the compress parameter when calling the clickhouse_connect.get_client factory method.
By default, compress is set to True, which will trigger the default compression settings. For queries executed
with the query, query_np, and query_df client methods, ClickHouse Connect will add the Accept-Encoding header with
the lz4, zstd, br (brotli, if the brotli library is installed), gzip, and deflate encodings to queries executed
with the query client method (and indirectly, query_np and query_df. (For the majority of requests the ClickHouse
server will return with a zstd compressed payload.) For inserts, by default ClickHouse Connect will compress insert
blocks with lz4 compression, and send the Content-Encoding: lz4 HTTP header.
The get_client compress parameter can also be set to a specific compression method, one of lz4, zstd, br, or
gzip. That method will then be used for both inserts and query results (if supported by the ClickHouse server.) The required
zstd and lz4 compression libraries are now installed by default with ClickHouse Connect. If br/brotli is specified,
the brotli library must be installed separately.
Note that the raw* client methods don't use the compression specified by the client configuration.
We also recommend against using gzip compression, as it is significantly slower than the alternatives for both compressing
and decompressing data.
HTTP Proxy Support
ClickHouse Connect adds basic HTTP proxy support using the urllib3 library. It recognizes the standard HTTP_PROXY and
HTTPS_PROXY environment variables. Note that using these environment variables will apply to any client created with the
clickhouse_connect.get_client method. Alternatively, to configure per client, you can use the http_proxy or https_proxy
arguments to the get_client method. For details on the implementation of HTTP Proxy support, see the urllib3
documentation.
To use a Socks proxy, you can send a urllib3 SOCKSProxyManager as the pool_mgr argument to get_client. Note that
this will require installing the PySocks library either directly or using the [socks] option for the urllib3 dependency.
JSON Data Type
The experimental JSON (or Object('json')) data type is deprecated and should be avoided in a production environment.
ClickHouse Connect continues to provide limited support for the data type for backward compatibility. Note that this
support does not include queries that are expected to return "top level" or "parent" JSON values as dictionaries or the
equivalent, and such queries will result in an exception.